Overview
As organizations scale their data ecosystems, decentralization allows data teams to manage and build products independently, fostering innovation and faster time to value. However, maintaining efficiency, governance, and control in this setup can be challenging. The solution is a Data Developer Platform (DDP) that balances autonomy with centralized control through standardized practices and an everything-as-code approach. This ensures consistency, reduces errors, and speeds up collaboration while maintaining governance and compliance across teams.
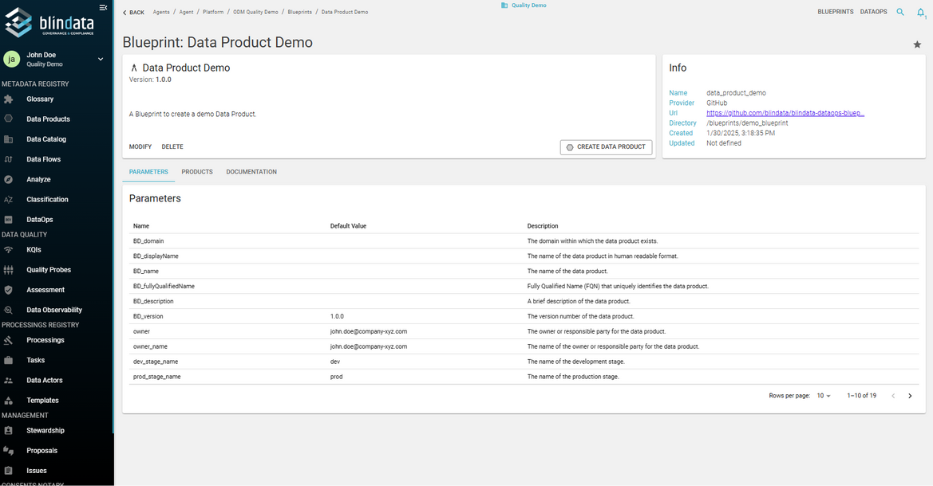
At the heart of the DataOps module is the notion of governance by design. Governance is not an afterthought—it is encoded and enforced from the start of the development process. Through blueprints, teams can define Git-based templates that encapsulate the expected structure, contracts, metadata, and quality requirements for any new data product. This ensures consistency while enabling self-serve capabilities across domains.
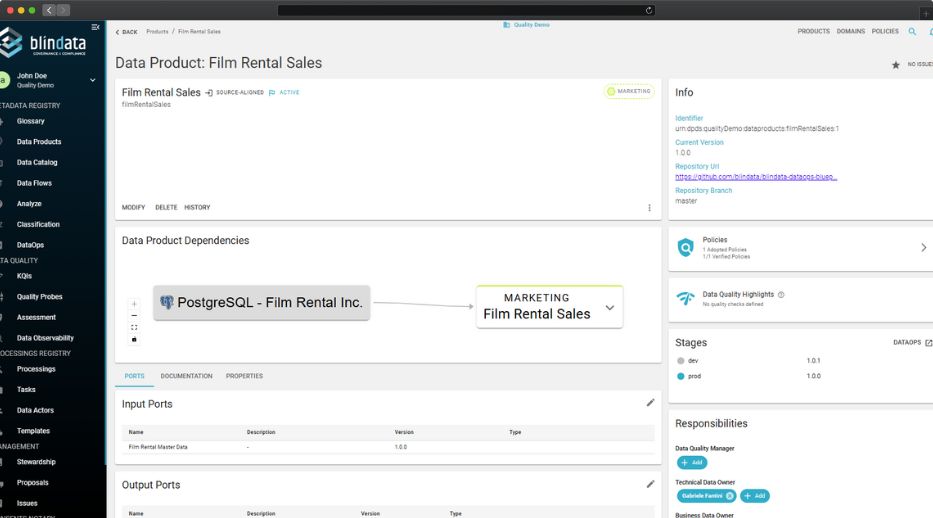
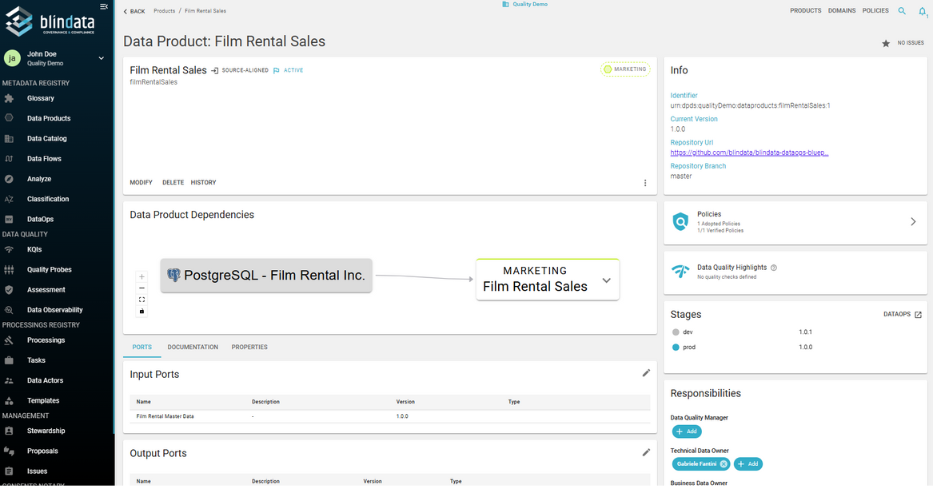
As data products evolve, Blindata provides tools for descriptor registration, lifecycle tracking, and computational policy enforcement. These features allow platform teams to monitor changes, evaluate compliance, and implement quality gates without interrupting development workflows. Data producers can iterate quickly, knowing that automated checks will safeguard standards and align with organizational requirements.
The module integrates natively with the Open Data Mesh open-source ecosystem, providing compatibility with community specifications and lifecycle automation tooling. This includes out-of-the-box support for domain registries, stewarding, authorization frameworks, and governance policies—positioning Blindata as a complete DataOps orchestration layer.
Whether you’re launching your first data product or scaling a federated data platform, the DataOps module provides the infrastructure and practices to sustain agility without compromising control.
Features
The DataOps module in Blindata equips platform and domain teams with everything they need to design, deploy, and govern data products in a consistent, scalable, and automated way.
Blueprints & Templates
Standardize the creation of data products using reusable, Git-backed blueprints that define structure, ports, policies, and documentation.
Lifecycle Management
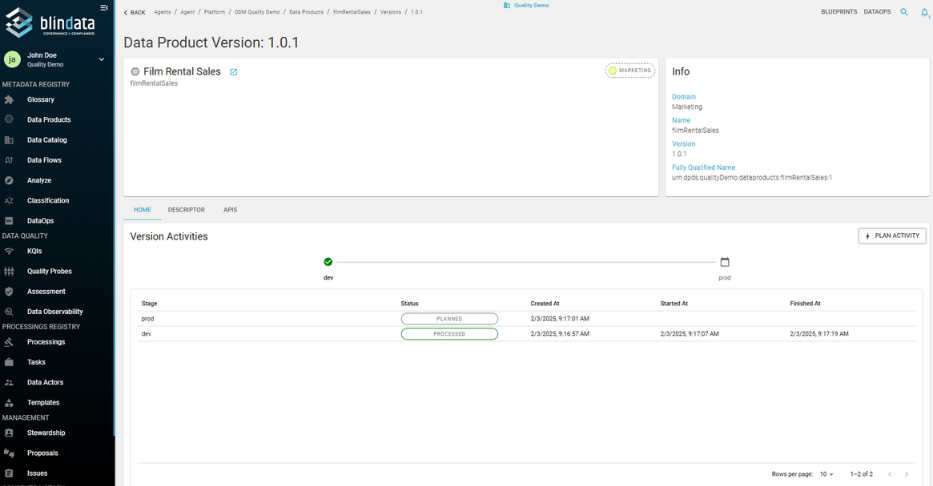
Track the full lifecycle of a data product, from draft to production, including version history, status transitions, and compliance stages.
Policy Enforcement
Automatically validate that data products meet quality, documentation, and governance requirements before they go live.
Data Product Descriptor Registry
Register and manage metadata descriptors in a standardized format to ensure consistency, discoverability, and automation across domains.
Federated Governance
Assign responsibilities, steward roles, and access rules across domains, while enforcing shared policies centrally.