
Introduction
Organizations aim to harness the potential of data to fuel innovation, enhance decision-making, and secure a competitive advantage. Decentralized data architectures and methodologies, like the Data Mesh, have arisen as a means to manage this. However, for a modular data platform, it is essential to maintain governance and control in a decentralized environment. This can be accomplished by establishing quality gates.
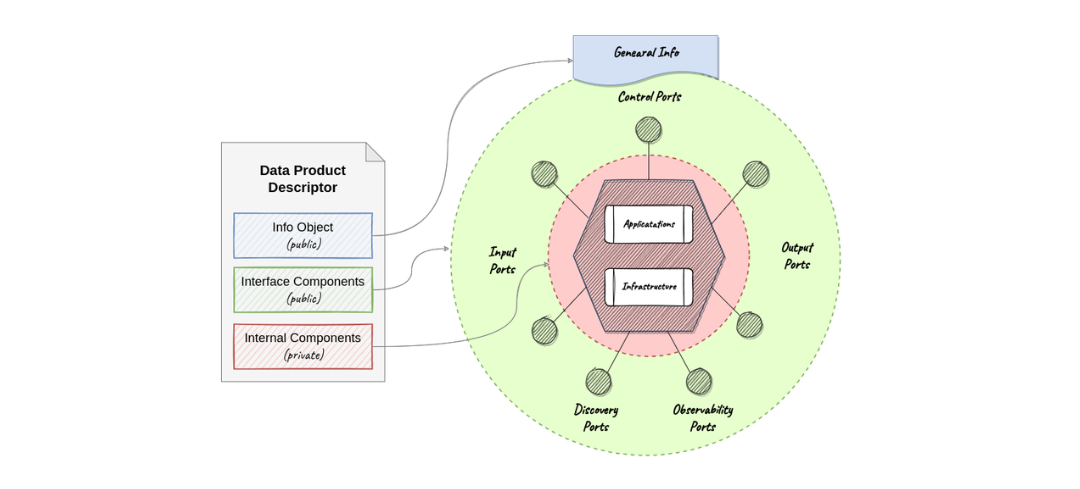
Data Products Descriptor
The first step in constructing quality gates is to adopt an “everything as code” philosophy, which promotes standardization and enables computational control through computational governance policies. To achieve this, an organization should implement a data product descriptor specification, such as the Open Data Mesh Descriptor Specification. A descriptor serves as a comprehensive guide to all information about a data product, including its interface and internal components. It is used to share a complete view of the data product between consumers and the underlying DataOps Platform throughout its lifecycle.
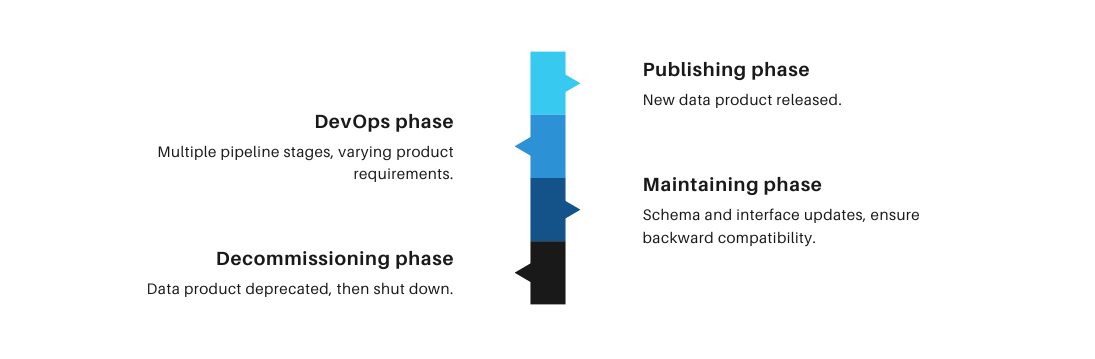
Data Products Lifecycle
The second step is to define and standardize the lifecycle of all data products. This aims to streamline processes, minimize errors, and enhance compliance with regulations and standards by eliminating inconsistencies. The main phases are:
- Publishing phase: Here, a new iteration of the data product is released, accompanied by comprehensive technical and non-technical metadata.
- Devops phase: Depending on the environment and configurations, there can be one or more pipeline stages, from development to production. Each stage may entail distinct requirements concerning data product characteristics, such as maturity.
- Maintaining phase: Following the release of the data product, infrastructural changes to schema and interfaces may occur. It is always a good practice to check about backward compatibility with previous releases.
- Decommissioning phase: Ultimately, the data product reaches the end of its lifecycle, becoming deprecated before being shut down.
Policy Types
Once the data product lifecycle has been defined, it becomes feasible to capture events with contextual information for evaluating computational policies. Each phase allows for the definition of various types of computational policies, covering different use cases and regulatory compliance requirements.
Policies on metadata
This policies enforce the adherence of the descriptor to the specification, granting that all the necessary metadata is present. This is critical to enable the shift-left approach.
Policies on stage transition
The correct flow through the DevOps pipeline stages can be ensured using this type of policies. For instance, it can prevent a data product from bypassing the development stage and going directly to production.
Policies on cloud resources configuration
Restrictions on cloud regions, backup policies, encryption settings and other organizational constraints can be enforced by this policies. They operate prior to the deployment of cloud resources, preventing undesired changes even before they take place. For example, such a policy could be implemented by verifying the Terraform plan.
Policies on backward compatibility
This policies ensure that breaking changes are avoided. Data contracts must maintain backward compatibility with previous versions. This involves controlling ports and interfaces to prevent any breaking changes that could negatively impact the data product dependencies.
Policies post deployment
After the data product has been deployed, this type of policies can be used to verify that cloud resources are coherent with what is declared inside the data product descriptor.
Policies on decommissioning
When a data product is being decommissioned, a computational policy can prevent the onboarding of new consumers to utilize the data product. This ensures a smooth transition and avoids any potential issues with new users accessing a product that will soon be obsolete.
Conclusion
In conclusion, the described approach can be achieved using Blindata, which seamlessly integrates with the Open Data Mesh Platform. By adopting an “everything as code” philosophy and implementing a data product descriptor specification, organizations can standardize the lifecycle of their data products and enforce computational policies to ensure compliance with regulations and standards. This approach allows for a shift-left approach, enabling the detection of issues early in the pipeline and reducing the risk of errors and inconsistencies. Blindata’s flexibility and adaptability to various tools and standards make it an ideal solution for organizations looking to harness the potential of data while maintaining control and governance in a decentralized environment.