Overview
Blindata Data Ops joins modern data management and governance in one delivery workflow: teams design, version, and publish data products while keeping metadata, contracts, and ownership current from the start. Platform-level computational policies control what can progress through the lifecycle, so the result is a managed path from blueprint to production, not a cleanup after go-live.
Features
Blindata Data Ops covers the full path from standardized creation to governed operation of data products.
Blueprints & standards
Reusable, versioned templates so new products start with structure, ports, documentation, and governance baked in. Platform teams encode best practices once; domain teams instantiate them self-serve.
Shift-left metadata
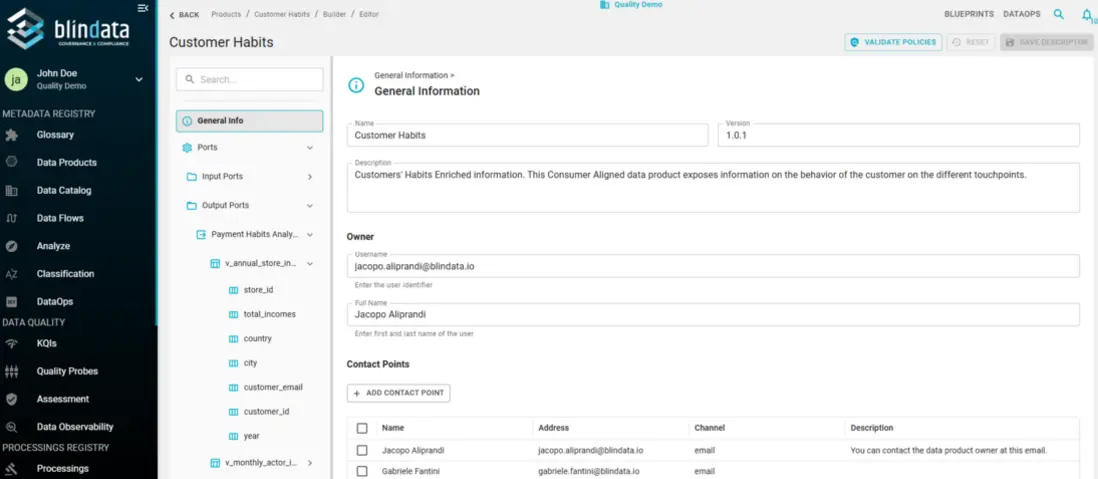
Edit the Data Product Descriptor in the Builder and commit to Git. Identity, ownership, ports, schemas, and business-glossary links stay current because they are authored before publication, not cleaned up afterward.
Data contracts
Producer–consumer agreements on schema, quality, and SLAs live on input and output ports inside the descriptor. Clear interfaces before data goes live. See Data Contracts.
Computational policies
Platform-level rules that govern the data product lifecycle: registration, version publishing, stage transitions, and deployment outcomes. The control plane for federated governance, not a substitute for contracts. See Computational Governance Policies.
Managed lifecycle
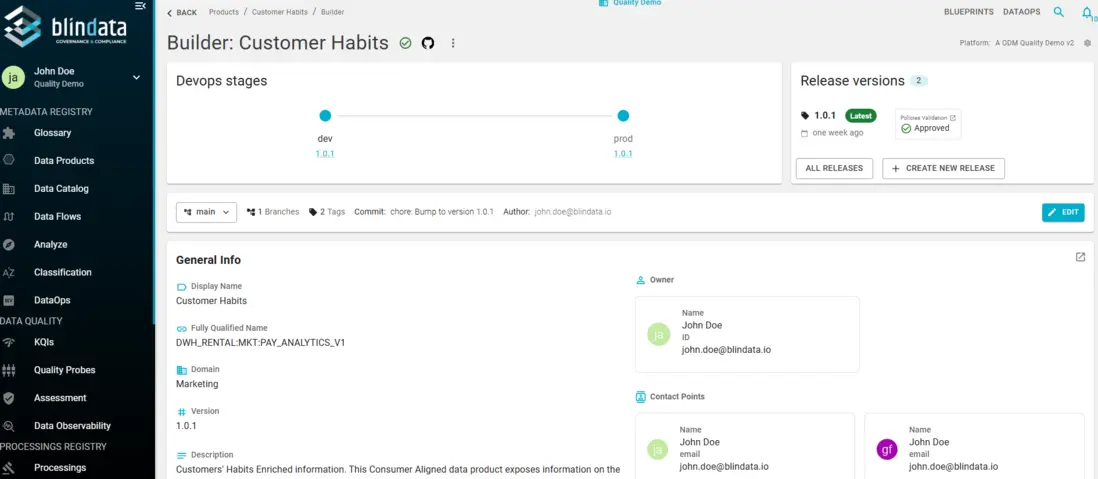
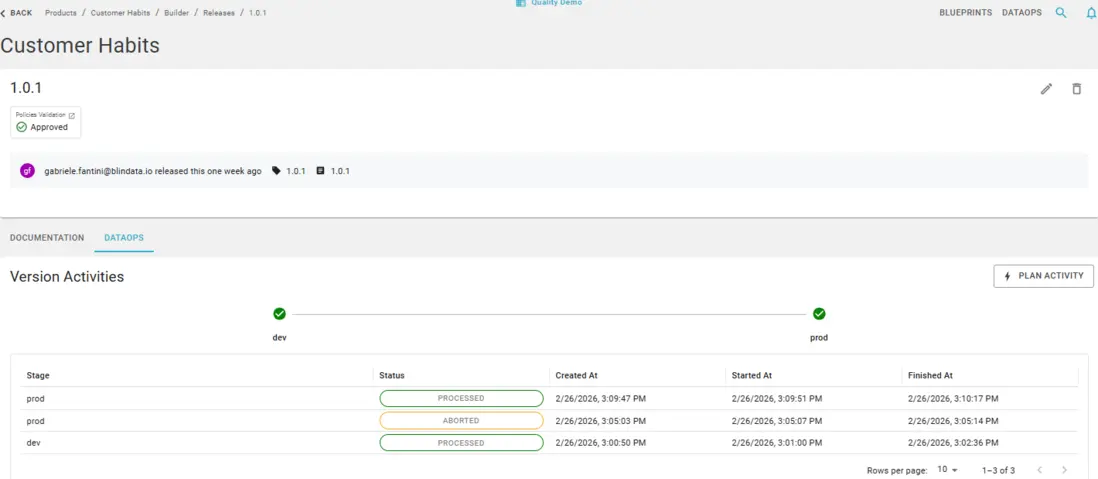
Init, build, and publish with immutable release versions; plan and run DevOps activities across stages such as dev, test, and prod. Traceability and promotion stay tied to the same governed descriptor.
Meaning at publish
Link port schemas to business glossary concepts when you ship, so the catalog and marketplace receive products that are already semantically grounded for discovery and reuse.
How to
Begin with a Blueprint from the catalog instead of a blank repository. Blueprints are versioned Git templates that encode infrastructure, pipeline configuration, descriptor structure, and governance defaults. Platform engineers publish approved versions; data product owners instantiate them with parameters and get a consistent, compliant starting point.
This is how standards scale: compliant delivery becomes the default path, setup time drops, and every new product inherits the same baseline for ports, documentation, and lifecycle stages.
Open the Data Product Builder and edit the descriptor as the product takes shape. The DPDS file in Git is the single source of truth for:
- General info: name, domain, ownership, contact points.
- Ports: input and output interfaces, schemas, and physical fields.
- Semantics: links from tables and fields to business glossary concepts and attributes.
- DevOps: activities and tasks that will run across lifecycle stages.
Save commits to the linked repository as you go. Shift-left means metadata is not a post-release chore: when the product is ready to publish, the catalog already reflects what was designed.
Define contracts on the ports while the product is still in development. Declare what each output port promises (schema, quality rules, freshness) and what each input port depends on. Quality annotations on the contract let product owners express monitoring expectations alongside the interface, not in a separate wiki.
Contracts are modular: start with schema and ownership, then add SLAs, breaking-change rules, and quality probes as the team matures. They are the agreement between producers and consumers. Deeper guidance lives on the Data Contracts page.
Computational policies are how the platform enforces global standards across every data product. They are automated rules triggered on lifecycle events such as product creation and update, version publishing, activity stage transitions, and task or activity results.
Use them to block non-compliant registration, enforce descriptor completeness and naming conventions, guard backward compatibility on new versions, validate stage transitions and deployment outcomes, or check infrastructure constraints (for example cloud region, backup, or encryption) before resources are applied. Blocking flags decide whether a violation stops progression or only records a finding.
Define and document policies once, deploy implementations (OPA or custom validators), and collect evaluation results centrally. Domain teams keep building; the platform keeps control. See Computational Governance Policies.
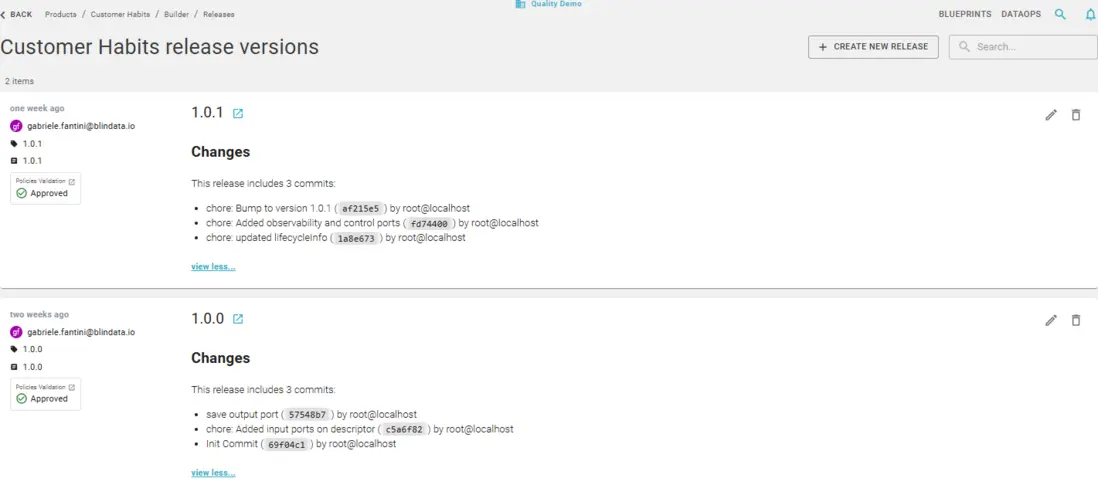
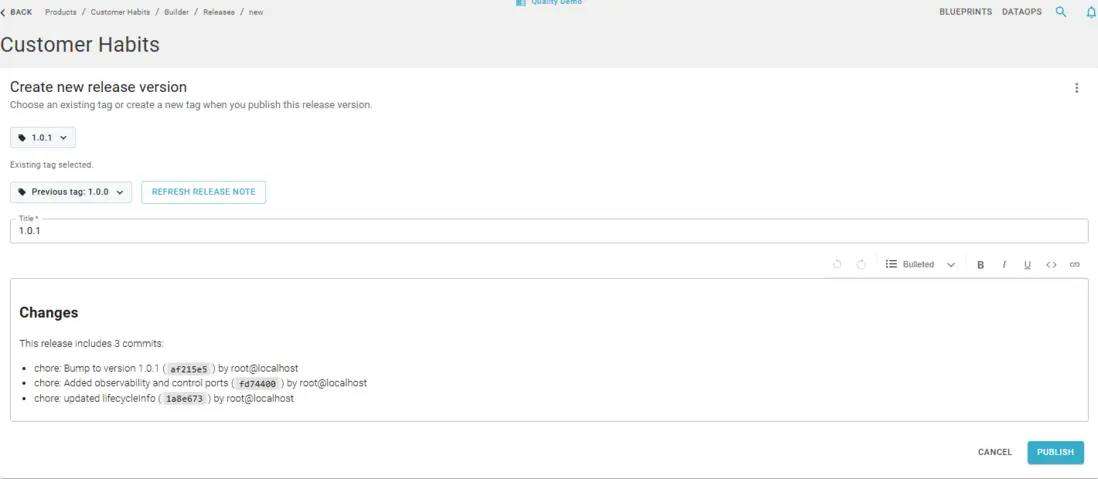
When the product is ready, create an immutable release version: tag the repository, add a changelog, and publish. The tag freezes the exact descriptor state for traceability and consumer compatibility. From there, plan and run DevOps activities defined in the descriptor across stages (for example dev, test, prod), so promotion is an intentional, auditable step rather than an ad-hoc deploy.
Ship with clear ownership and semantic links already in place. What lands in the Data Products Catalog and marketplace is the same governed artifact teams built, not a separate documentation exercise after the fact.
After go-live, keep treating the product as a living asset. Track which version sits in each stage, review policy evaluation results from registration and promotion events, and resolve drift in contracts, ownership, or semantic links before it becomes a downstream incident. Update blueprints and platform policies as organizational standards evolve so the next products inherit the improved baseline.
Stewards and product owners get actionable signals from both lifecycle policy evaluations and quality probes on contracted assets. Governance stays embedded in operations instead of becoming a periodic cleanup program.