
Introduction
In the age of large language models (LLMs) and advanced artificial intelligence, ontologies have experienced a significant resurgence. Originally developed for organizing complex domains of knowledge, ontologies are now crucial in enabling machines to understand and reason about data with greater precision. This renewed interest is driven by the need for LLMs to engage with structured, domain-specific semantics—allowing them to generate more accurate and contextually relevant outputs.
As data continues to grow in complexity and volume, ensuring that it is semantically rich and well-organized has become a key responsibility within data governance. Proper semantic structuring not only improves current data utility but also future-proofs it, making it adaptable for new and emerging technologies. These technologies, especially LLMs, will increasingly rely on domain-specific semantics to fully unlock their potential, meaning that today’s investment in ontology development is an investment in tomorrow’s AI capabilities.
What is an Ontology?
At its core, an ontology is a formal representation of knowledge within a particular domain. It defines the types of things (entities) that exist in that domain and the relationships between them. Think of an ontology as a detailed blueprint or map of a specific knowledge area, such as biology, finance, or e-commerce, where each element of data has a clearly defined meaning and role.
Ontologies consist of classes (representing concepts), properties (representing attributes or relationships), and instances (representing individual examples of these concepts). For example, in a healthcare ontology, “Patient” might be a class, “hasDisease” might be a property linking a patient to a disease, and “John Doe” might be an instance of the class “Patient”.
Data as a Knowledge Graph
An essential idea connected to ontologies is the concept of a Knowledge Graph. A knowledge graph represents data as a network of entities and the relationships between them. Unlike traditional databases, which store data in tables, knowledge graphs store data as interconnected nodes and edges, where nodes represent entities, and edges represent the relationships between them.
A key technical foundation of a knowledge graph is that it is a collection of triples—comprising a subject, predicate, and object. These triples form the building blocks of the graph: the subject represents the entity, the predicate defines the relationship, and the object represents another entity or value. For instance, in a knowledge graph, the triple (“Product A”, “is a type of”, “Electronics”) defines an entity, its classification, and the relationship between them. This triple-based approach enables the rich and flexible representation of data.
However, to govern and interpret the data stored in a knowledge graph, there is a need for a guiding framework—a schema. This is where ontologies come into play, providing a semantic layer that gives structure to the knowledge graph. Ontologies define the rules, classes, properties, and relationships that enable the interpretation, querying, and validation of the underlying data. They ensure that data is semantically rich, accurate, and meaningful, regardless of the complexity of the relationships.
In practice, knowledge graphs can be implemented in two ways: materialized or virtualized. A materialized knowledge graph consolidates data into a centralized graph database, allowing for powerful analytics and reasoning. In contrast, a virtualized knowledge graph operates in a distributed environment, where data remains in its original systems but can be queried and connected through the ontology. The ontology schema plays a crucial role in this virtualized setup, serving as a navigational map that links disparate data sources across systems, ensuring that they are semantically consistent and interoperable.
This virtualized knowledge graph is particularly important in modern data ecosystems where data is often spread across different platforms, systems, or even geographies. The ontology-driven semantic layer becomes essential for navigating this distributed data landscape, allowing for seamless querying and interpretation without the need to centralize all data physically. Instead, the ontology provides a coherent structure, connecting data products, systems, and repositories, ensuring that they can be accessed, understood, and used cohesively.
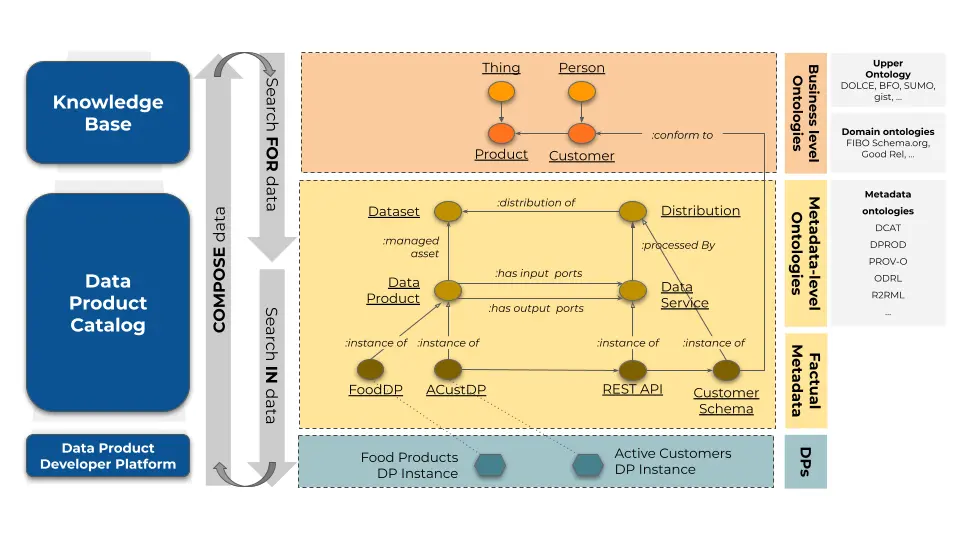
In this case, data products are semantically connected to the ontology-driven semantic layer, providing a unified and meaningful view across a fragmented data environment. The ontology acts as a semantic glue, ensuring that distributed data sources are integrated and navigable, enabling organizations to extract value from their knowledge graph even when their data is scattered across multiple systems.
Regardless of the underlying technology—whether it’s relational databases, NoSQL systems, or cutting-edge graph databases—the graph representation of data is inherently more natural and intuitive. In a knowledge graph, data is organized as a network of entities (nodes) connected by relationships (edges), reflecting the way humans naturally perceive the world. Defining the semantics of data should be agnostic to the technology used to store or process it. The structure and meaning of data need to transcend the limitations of specific systems to ensure longevity and adaptability. This is where traditional business glossaries often fall short. While these glossaries list terms and definitions, they lack the depth to capture the intricate relationships and context necessary for true semantic understanding.
To model semantics effectively, we need more than just a list of terms; we need a structured, interconnected system that reflects the complexity and richness of the domain. Knowledge graphs, guided by ontologies, enable this by embedding meaning directly into the data structure, allowing for more sophisticated search, reasoning, and analysis. This approach not only enriches the data but also ensures it remains meaningful and useful across different technologies and applications.
Building an effective semantic layer requires a deep focus on the same concept of ontology schema that provides structure, properties, and cohesion to a knowledge graph. By defining clear relationships, rules, and hierarchies, an ontology can ensure that the data is not only organized but also semantically coherent. This interconnected semantic layer empowers organizations to make sense of complex, distributed data landscapes, providing a unified view that is both adaptable and future-proof.
Taxonomies and Ontologies
Taxonomies are hierarchical classifications that organize information into parent-child relationships. In a traditional business glossary, a taxonomy categorizes terms into broader categories and subcategories, offering a straightforward way to navigate different concepts. For example, in a retail business glossary, “Products” might be a parent category, with “Electronics,” “Apparel,” and “Home Goods” as subcategories. Taxonomies excel at establishing clear, navigable structures within a domain, making them useful for simple categorization and information retrieval.
However, taxonomies have limitations in representing complex relationships and contextual nuances. They are inherently rigid, with a single-path hierarchy that doesn’t capture the multi-dimensional nature of real-world knowledge.
Traditional business glossaries and taxonomies can serve as a solid foundation for building a semantic layer, creating an initial structure that organizes and classifies concepts. As organizations evolve and require a more nuanced understanding of relationships, this foundational layer can be expanded into an ontology.
Ontologies offer a more sophisticated and flexible framework for modeling knowledge. Unlike taxonomies, which are limited to hierarchical relationships, ontologies can represent a wide range of relationships between concepts, such as “is a type of,” “is related to,” or “is part of.” This flexibility makes ontologies particularly powerful for enhancing a business glossary, enabling it to not only list terms but also embed rich semantic relationships within and across categories.
For instance, in an ontology-driven semantic layer, “Electronics” might be related to “Consumer Goods” through an “is a type of” relationship, while also being linked to “Warranties” through a “requires” relationship. These connections allow for a more comprehensive understanding of how different terms and concepts interact within the business domain.
Thus, while a business glossary and taxonomy provide a simple, clear structure for navigating terms and categories, an ontology builds upon this foundation to offer richer, more complex relationships and insights. Taxonomies deliver the simplicity needed for basic organization, while ontologies provide the expressiveness required to manage intricate, evolving knowledge domains. This layered approach allows organizations to progress from basic semantic management to a more sophisticated knowledge framework.
Conceptual Modeling: Ontologies and ERDs
When structuring information, Entity-Relationship Diagrams (ERDs) and ontologies each play crucial roles, but they are tailored to address different types of problems and contexts.
Entity-Relationship Diagrams (ERDs) excel at modeling data in structured environments with well-defined schemas. They are ideal for designing relational databases, where relationships between entities are clearly specified and the system operates in a controlled, closed environment. ERDs are particularly effective for structured data modeling, ensuring data consistency and integrity by enforcing strict adherence to predefined schemas. This makes ERDs well-suited for scenarios where data is uniform, stable, and centralized. However, when the content is semi-structured or unstructured, ERDs can quickly become cumbersome, as their rigid structure does not easily accommodate more fluid or unpredictable relationships.
Ontologies, by contrast, focus on modeling knowledge and thrive in more complex, dynamic environments. Ontologies are ideal when information is highly interconnected, and where relationships between entities are not strictly hierarchical or predictable. They are built to handle open-world problems, where there is no closed schema, and data is distributed across multiple systems or even publicly accessible. Ontologies allow for flexibility and adaptability, enabling the representation of knowledge that evolves over time, making them particularly effective for open environments where data structures and relationships are in flux.
The fundamental difference between ERDs and ontologies lies in their underlying assumptions and intended use. ERDs are designed for closed, controlled systems where data and relationships are well-defined and stable. Ontologies, represented through standards like RDF, are designed for open, distributed systems, where interoperability and complex relationships are essential. Ontologies provide a semantic framework for integrating information from disparate sources, enabling sophisticated knowledge representation that can adapt to changing data landscapes.
This isn’t a matter of superiority but of choosing the right tool for the task at hand. Both ERDs and ontologies are valuable depending on the problem being addressed. ERDs are most effective when working with traditional, relational databases in closed systems, while ontologies shine when dealing with graph structures or integrating data across distributed systems where control over data is limited or non-existent.
In summary, while ERDs offer a robust solution for modeling structured data in stable, well-defined environments, ontologies provide the flexibility and expressiveness needed to represent complex knowledge in open, evolving scenarios. Understanding the strengths and limitations of each approach ensures that you can select the most appropriate tool for accurately modeling your data or knowledge.
Ontologies Representation: RDF and RDFS
To technically represent ontologies, we use standards such as RDF (Resource Description Framework) and RDFS (RDF Schema).
- RDF (Resource Description Framework): RDF is a framework for representing information about resources on the web. It describes resources in the form of triples: subject, predicate, and object. For example, “John Doe hasDisease Hypertension” can be represented as a triple, where “John Doe” is the subject, “hasDisease” is the predicate, and “Hypertension” is the object.
- RDFS (RDF Schema): RDFS extends RDF by providing mechanisms to define the classes and properties that will be used in the RDF data. It allows us to define hierarchies of classes and properties, adding more structure to our data.
Turtle (Terse RDF Triple Language) is a syntax for writing RDF data. Below are some examples that illustrate how RDF and RDFS work together.
Defining Classes and Instances:
@prefix ex: <http://example.org/> .
ex:Person rdf:type rdfs:Class .
ex:Disease rdf:type rdfs:Class .
ex:JohnDoe rdf:type ex:Person .
ex:Hypertension rdf:type ex:Disease .
- Here, we define Person and Disease as classes, and JohnDoe and Hypertension as instances of those classes.
Defining Properties:
ex:hasDisease rdf:type rdf:Property ;
rdfs:domain ex:Person ;
rdfs:range ex:Disease .
ex:JohnDoe ex:hasDisease ex:Hypertension .
- The hasDisease property is defined with a domain of Person and a range of Disease, meaning it can link instances of Person to instances of Disease. We then assert that JohnDoe has the disease Hypertension.
Creating Hierarchies:
ex:ChronicDisease rdfs:subClassOf ex:Disease .
ex:Hypertension rdf:type ex:ChronicDisease .
- Here, ChronicDisease is defined as a subclass of Disease, and Hypertension is further classified as a ChronicDisease.
In conclusion, when defining the semantic layer, RDF Schema (RDFS) plays a critical role as the foundational model for structuring and understanding the underlying data. While RDF provides the basic framework for representing data as triples (comprising subjects, predicates, and objects). RDFS extends this by enabling the creation of a hierarchical structure. This allows for organizing classes into subclasses and defining properties with specific domains and ranges. Such hierarchical organization is essential for modeling complex relationships and ensuring consistency in how data is interpreted and related. RDFS thus serves as the backbone of the semantic layer, ensuring that the data is not only well-structured but also semantically meaningful.
Conclusion
Ontologies are powerful tools for modeling the semantics of data, particularly in complex domains where understanding relationships between entities is key. They form the backbone of knowledge graphs, which are indispensable for enabling machines to process and reason about data in a human-like manner. Through standards like RDF and RDFS, we can technically represent ontologies in a structured and machine-readable format, paving the way for more advanced applications in AI, including large language models. By combining the principles of conceptual modeling with the expressiveness of ontologies, we can create rich, interconnected data systems that not only store information but also embody knowledge.
Blindata empowers your organization to govern its knowledge architecture effectively by implementing a robust, ontology-driven semantic layer. Our approach ensures that your data is organized in a way that mirrors the complexity and richness of your domain, facilitating precise and meaningful interactions across various systems.
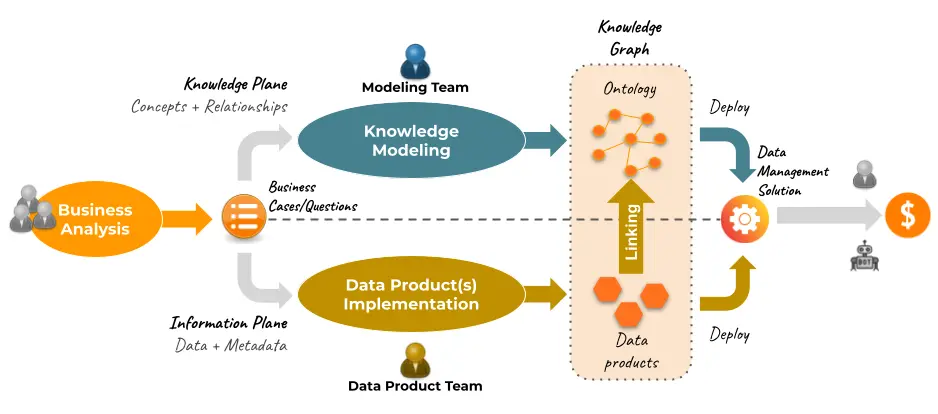
By defining a comprehensive ontology, we create a structured framework that captures intricate relationships, enhances data interoperability, and ensures semantic composability. Blindata allows you to catalog your data products and manage their semantic linking to the business ontology, providing a solid foundation for advanced analytics and consistent data management. This semantic layer not only improves the clarity and consistency of your data but also future-proofs it, enabling seamless integration and adaptability as your data needs evolve.