Overview
Understanding the origin and transformations of your data is crucial for data quality, governance, and compliance. In complex architectures like data lakehouses, with diverse sources, multi-stage transformations, and intertwining data flows, unraveling the data lineage can be daunting.
With Blindata’s Automated SQL Lineage and its compatibility with Redshift—an ideal platform for implementing data lakehouse architectures and performing ELT jobs—you can effortlessly gain a comprehensive understanding of your data’s journey.
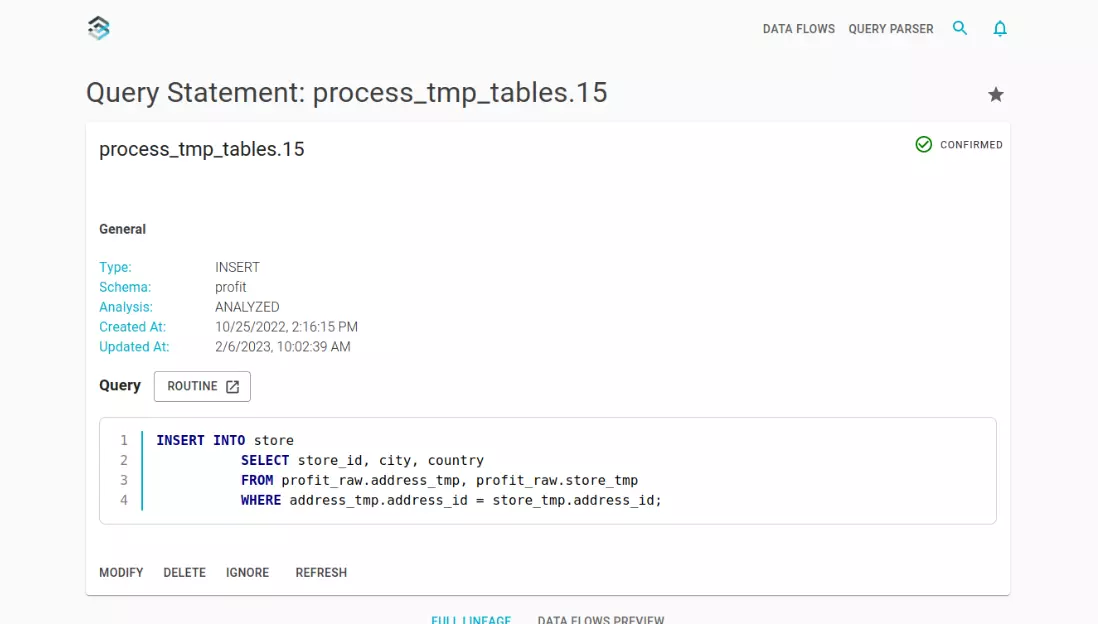
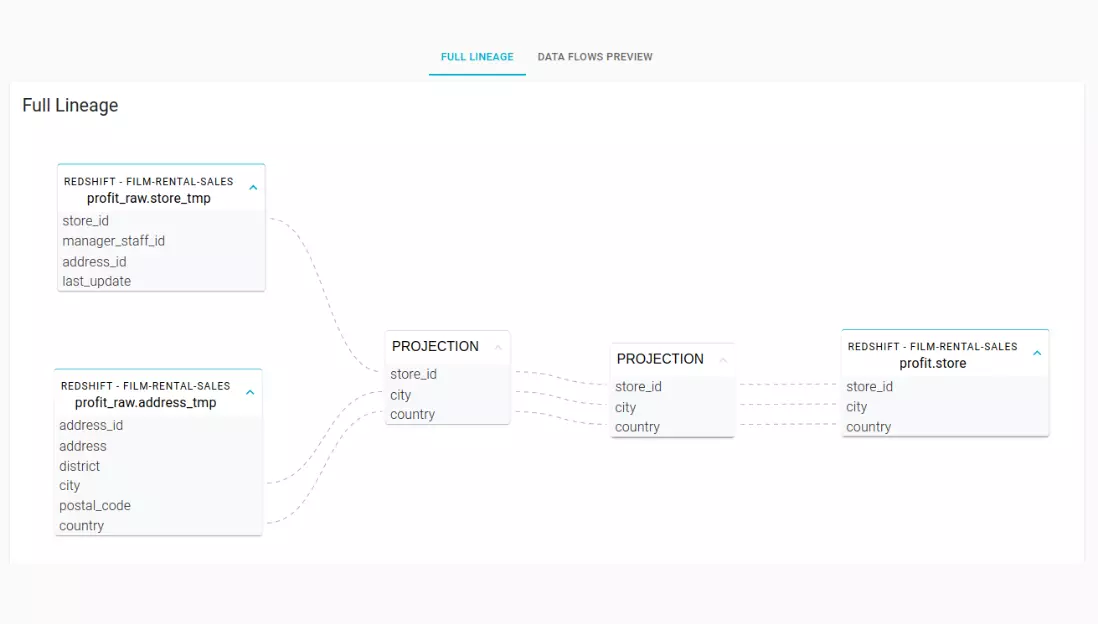
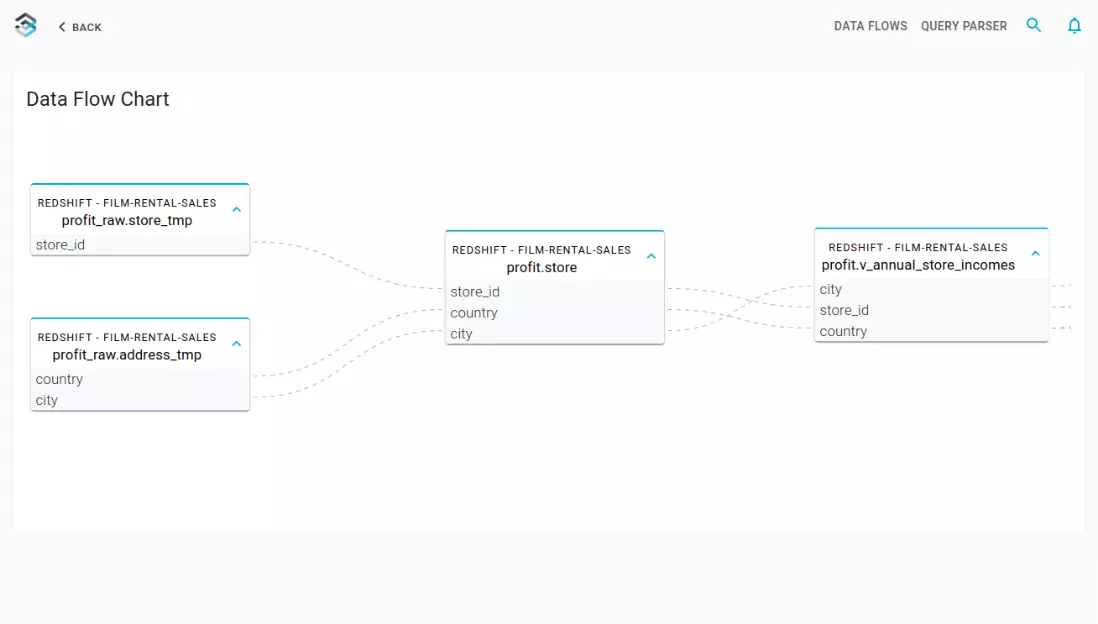
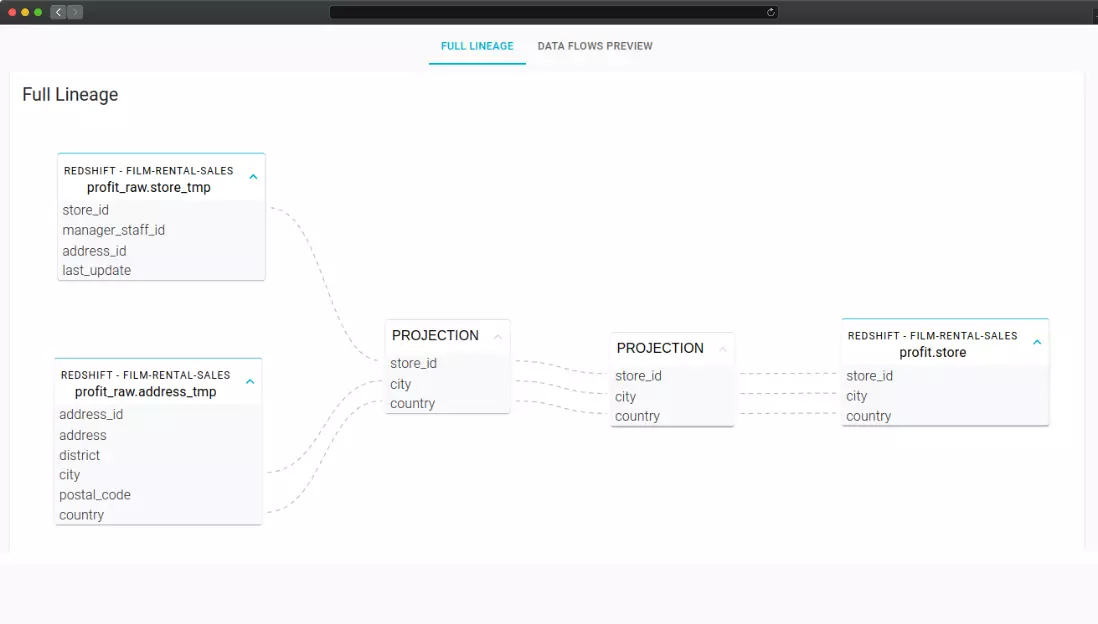
By automatically analyzing table metadata and SQL scripts, Blindata reconstructs the internal data lineage, providing clear insights into sources, dependencies, and transformations. With this enhanced visibility, you can effortlessly trace your data’s journey from origin to final results. This blog post covers internal data movements implemented via views or ELT SQL statements, for other sources of data lineage such as provenance of S3 files or spark jobs lineage please refer to the AWS Glue Data Catalog documentation.
Context
Redshift is a cloud-based data warehouse that allows you to analyze structured and semi-structured data using SQL and other tools, with features such as scalability, performance, and data sharing. Redshift supports a data lakehouse architecture, which merges the benefits of data lakes and data warehouses in one platform. In this typical scenario, the architecture usually involves the use of:
- Amazon S3, which serves as a central data lake for all your data sources and analytics tools
- AWS Redshift Spectrum to query data directly in the S3 data lake without loading or duplicating the dataset
- SQL-based ELT transformations are then directly performed on Spectrum external tables
ELT statements can cause governance issues if they are not well documented because they may involve complex SQL scripts, various dependencies, assumptions, and side effects that are not obvious or traceable to other users or systems. Without good documentation, it can be hard to identify which data sources the dataset is based on and what is the impact of the transformations. Moreover, it can be difficult to manage, audit, and debug the ELT processes, especially if they involve multiple data sources, transformation layers, and destinations. Therefore, it is important to have a clear and consistent documentation strategy that does not mean looking at the pipeline source code whenever a question occurs.
Metadata
Blindata Automated SQL lineage module works by interpreting table metadata along with the SQL queries that generated the given table. According to the development techniques used to ingest and transform the data Blindata can perform static source code analysis by inspecting routines or scripts as well as dynamic analysis by inspecting the query logs of Redshift. Here are some useful sources of information about the location where the Automated SQL Lineage engine may fetch metadata.
You can use the SVV_ALL_TABLES and SVV_ALL_COLUMNS in Redshift to query metadata information about your Redshift objects, such as tables and columns.
For example, to list all tables and columns, you can use the following query:
select * from SVV_ALL_TABLES;
select * from SVV_ALL_COLUMNS;
These tables include standard tables as well as external tables. External tables are for example the ones that point to S3 buckets via AWS Redshift Spectrum or the ones used for cross-database queries. Use SVV_EXTERNAL_TABLES and SVV_EXTERNAL_COLUMNS to get more information. This step is fundamental to properly reconstructing the SQL syntax tree as it enables the discovery of all the columns and their ordinal positioning inside a table.
To get information about views and their definitions, you can use the INFORMATION_SCHEMA.VIEWS view. This view contains metadata about views, such as their names, definitions, and standard SQL settings.
For example, to list all views in a dataset, you can use the following query:
SELECT * FROM information_schema.views
where table_schema not in ('information_schema', 'pg_catalog');
Pay attention to the permission required to view the view_definition column: the user has the be the owner of the view otherwise that column would be set to null.
To get information about routines and their definitions, you can use the pg_catalog.pg_proc table. This table contains metadata about routines, such as their names, types, definitions, and languages.
For example, to list all routines in a dataset, you can use the following query:
SELECT n.nspname, b.usename, p.proname, p.prosrc
FROM pg_catalog.pg_namespace n
JOIN pg_catalog.pg_proc p ON pronamespace = n.oid
join pg_catalog.pg_user b on b.usesysid = p.proowner
where nspname not in ('information_schema', 'pg_catalog')
To get information about query logs, you can use several redshift tables such as:
- STL_QUERY and STL_QUERYTEXT contain the log about queries such as select, select into, insert, update, and create table as select (CTAS).
- STL_DDLTEXT captures DDL statements such as create table and create view statements.
- SVL_STATEMENTTEXT contains a complete record of all of the SQL commands that have been run on the system.
For example, to list all queries in a time range, you can use the following query: With this approach, you can intercept query commands launched by external ELT tools such as DBT, scripts or other data preparation tools.
The Automated SQL Lineage module uses this metadata to trace the data lineage from the bottom up. Blindata examines each SQL statement to build the syntax tree of the SQL command. Then the engine can produce the data lineage by following the syntax tree links from the source tables to the target tables.