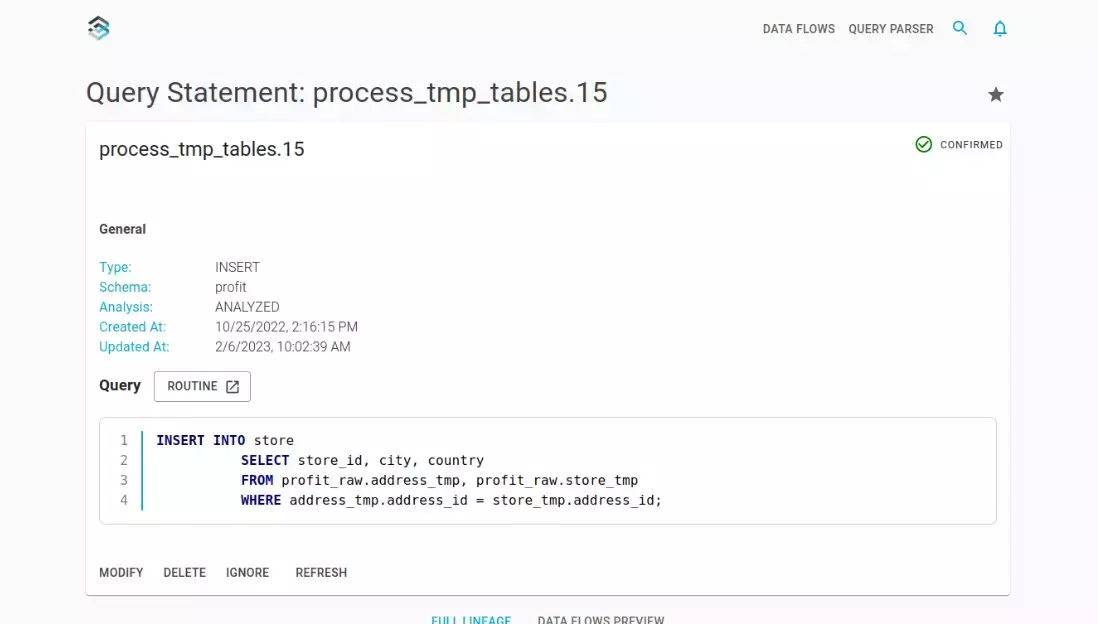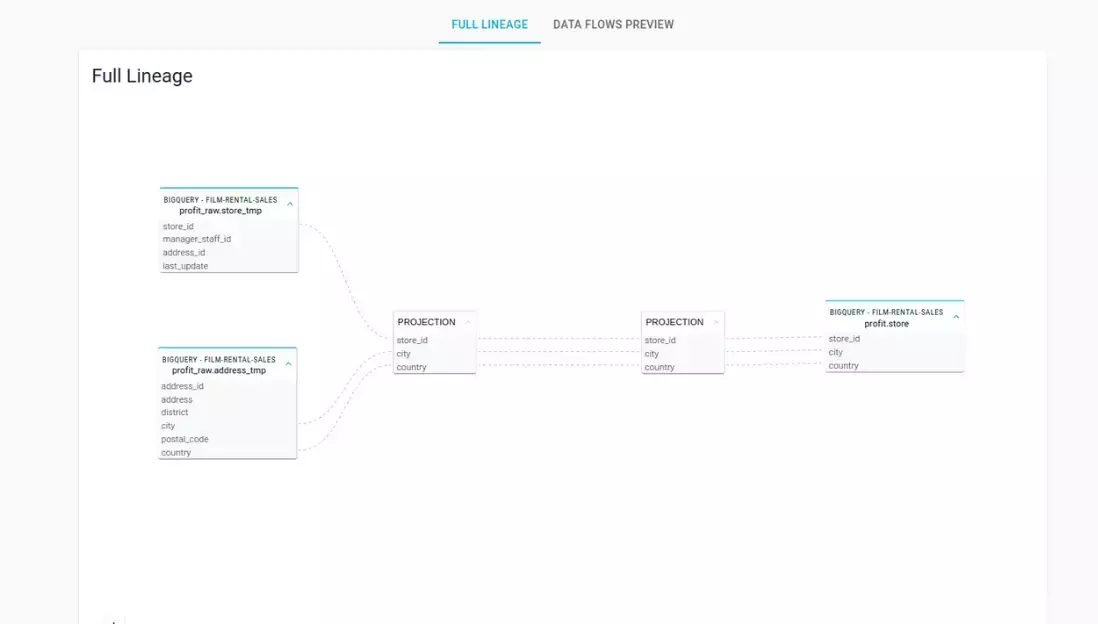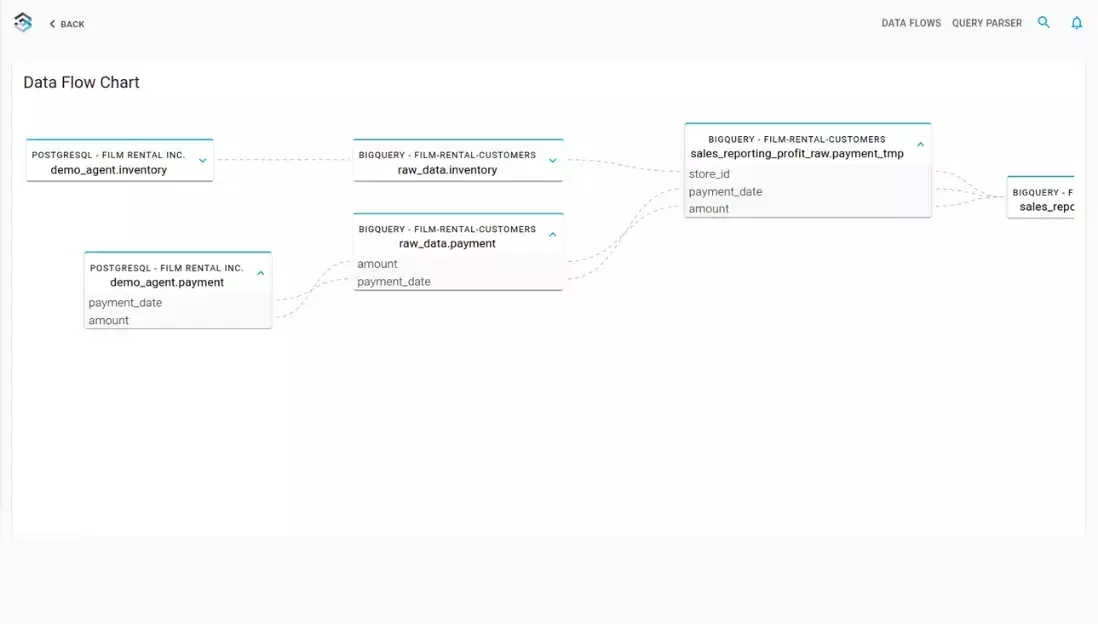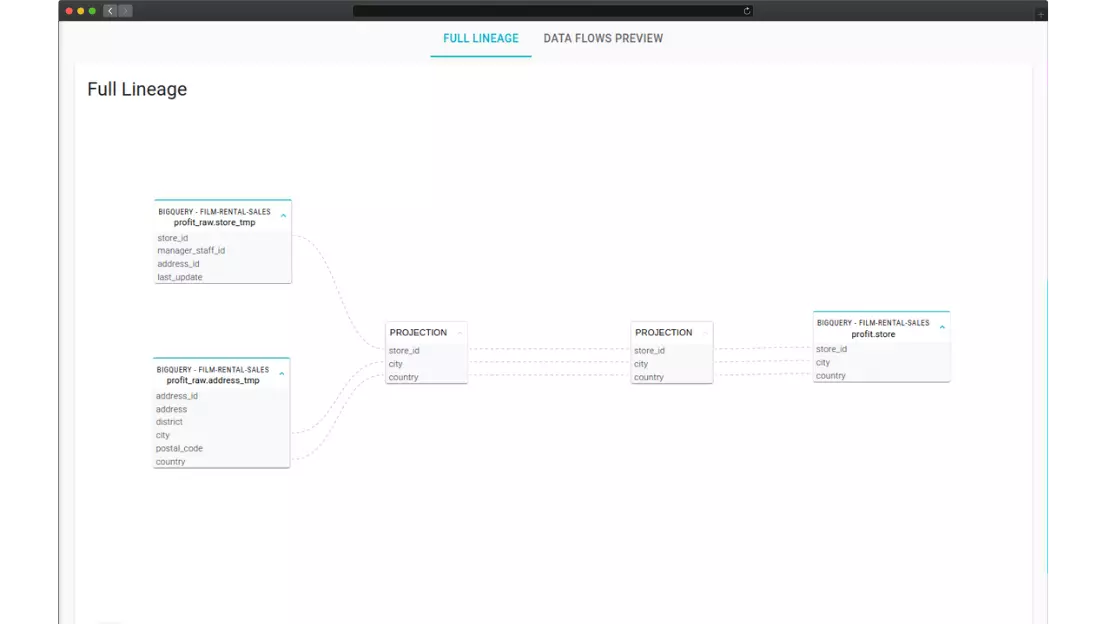
Overview
Data lineage is the process of tracing the origin, movement, and transformation of data in a database. It is essential for data quality, governance, and compliance, but it can be challenging to achieve, especially in complex and dynamic environments. In this article, we explore how Blindata’s Automated SQL Lineage can help reverse data lineage on Big Query, that is, to identify the sources and dependencies of a given data element. We use a case study approach to demonstrate how Blindata’s Automated SQL Lineage can extract data lineage information from SQL queries, scripts, and pipelines, and visualize it in an interactive graph.
Introduction
BigQuery is a serverless, highly scalable, and cost-effective data warehouse that is designed for the cloud. BigQuery supports a data lakehouse architecture, which combines the best features of data lakes and data warehouses in a single platform. A data lakehouse enables you to ingest and analyze data from a variety of sources using SQL and other tools usually performing ELT (extract, load, and transform) transformations or views, which allow you to load raw data into BigQuery and then apply transformations using SQL scripts on top of the data warehouse. This way, you can leverage the power and performance of BigQuery to process large volumes of data without the need for complex ETL pipelines.
The lineage generated by ELT statements can be a governance nightmare if not documented properly because they may involve complex SQL scripts, various dependencies, assumptions, and side effects that are not visible or traceable to other users or systems. If the lineage is not documented properly, it can be difficult to understand from which data sources the dataset is generated and what is the impact of the transformations. Moreover, it can be challenging to monitor, audit, and debug the ELT processes, especially if they involve multiple data sources, transformation layers, and destinations. Therefore, it is important to have a clear and consistent documentation strategy that does not imply reviewing the given pipeline source code whenever a question arises.
Metadata
Blindata Automated SQL lineage module works by interpreting dataset metadata along with the SQL queries that generated the given dataset. According to the development techniques used to ingest and transform the data Blindata can perform static source code analysis by inspecting routines or scripts as well as dynamic analysis by inspecting the jobs log tables of Big Query. Here are some useful sources of information to fetch metadata for the Automated SQL Lineage engine.
You can use the information_schema views in BigQuery to query metadata information about your BigQuery objects, such as tables and columns.
For example, to list all tables in a dataset, you can use the following query:
SELECT * FROM `myproject`.mydataset.INFORMATION_SCHEMA.TABLES;
SELECT * FROM `myproject`.mydataset.INFORMATION_SCHEMA.COLUMNS;
You can replace myproject and mydataset with your project ID and dataset ID respectively. This step is fundamental to discovering column positioning inside the table and properly reconstructing the SQL syntax tree.
To get information about views and their definitions, you can use the INFORMATION_SCHEMA.VIEWS view. This view contains metadata about views, such as their names, definitions, and standard SQL settings.
For example, to list all views in a dataset, you can use the following query:
SELECT * FROM `myproject`.mydataset.INFORMATION_SCHEMA.VIEWS;
You can replace myproject and mydataset with your project ID and dataset ID respectively.
To get information about routines and their definitions, you can use the INFORMATION_SCHEMA.ROUTINES view. This view contains metadata about routines, such as their names, types, definitions, and languages.
For example, to list all routines in a dataset, you can use the following query:
SELECT * FROM `myproject`.mydataset.INFORMATION_SCHEMA.ROUTINES;
You can replace myproject and mydataset with your project ID and dataset ID respectively.
To get information about query logs, you can use the INFORMATION_SCHEMA.JOBS_BY_PROJECT view to query metadata information about jobs in a project, such as their types, statuses, start and end times, and query statements.
For example, to list all query jobs in a project, you can use the following query:
SELECT * FROM `myproject`.`region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE job_type = 'QUERY';
You can replace myproject and region-us with your project ID and region respectively.
You can also use the Cloud Audit Logs feature of Google Cloud. This feature provides audit logs for BigQuery that provide insight regarding queries and the use of BigQuery services.